1. 什么是语言模型?
一句话,语言模型是这样一个模型:对于任意的词序列,它能够计算出这个序列是一句话的概率。
从文本生成角度来看,语言模型可以定义为:给定一个短语(一个词组或一句话),语言模型可以生成(预测)接下来的一个词。



2. Transformer
Transformer 是谷歌大脑 2017 年论文《Attentnion is all you need》中提出的 seq2seq 模型,现已获得了大范围扩展和应用。而应用的方式主要是:先预训练语言模型,然后把预训练模型适配给下游任务,以完成各种不同任务,如分类、生成、标记等。
Transformer算法采用 self-attention 机制实现快速并行;此外,Transformer 还可以加深网络深度,不像 CNN 只能将模型添加到 2 至 3 层,这样它能够获取更多全局信息,进而提升模型准确率。
Transformer 结构
如下是用 Transformer 进行中英文翻译的示例图:
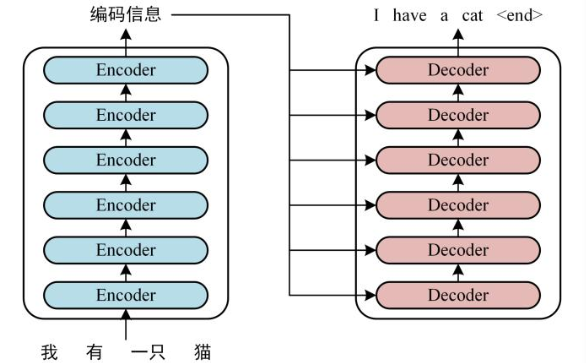
Transformer 由两大部分组成:编码器(Encoder) 和解码器(Decoder),每个模块都包含 6 个 block。所有的编码器在结构上都是相同的,负责把自然语言序列映射成为隐藏层,它们含有自然语言序列的表达式,但没有共享参数。然后解码器把隐藏层再映射为自然语言序列,从而解决各种 NLP 问题。
就上述示例而言,具体的实现可以分如下三步完成:
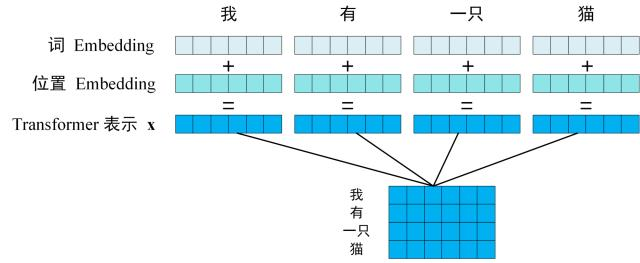
第一步:获取输入单词的词向量 X,X 由词嵌入和位置嵌入相加得到。其中词嵌入可以采用 Word2Vec 或 Transformer 算法预训练得到,也可以使用现有的 Tencent_AILab_ChineseEmbedding。
由于 Transformer 模型不具备循环神经网络的迭代操作,所以我们需要向它提供每个词的位置信息,以便识别语言中的顺序关系,因此位置嵌入非常重要。模型的位置信息采用 sin 和 cos 的线性变换来表达:
PE(pos,2i)=sin(pos/100002i/d)
PE (pos,2i+1)=cos(pos/100002i/d)
其中,pos 表示单词在句子中的位置,比如句子由 10 个词组成,则 pos 表示 [0-9] 的任意位置,取值范围是 [0,max sequence];i 表示词向量的维度,取值范围 [0,embedding dimension],例如某个词向量是 256 维,则 i 的取值范围是 [0-255];d 表示 PE 的维度,也就是词向量的维度,如上例中的 256 维;2i 表示偶数的维度(sin);2i+1 表示奇数的维度(cos)。
以上 sin 和 cos 这组公式,分别对应 embedding dimension 维度一组奇数和偶数的序号的维度,例如,0,1 一组,2,3 一组。分别用上面的 sin 和 cos 函数做处理,从而产生不同的周期性变化,学到位置之间的依赖关系和自然语言的时序特性。
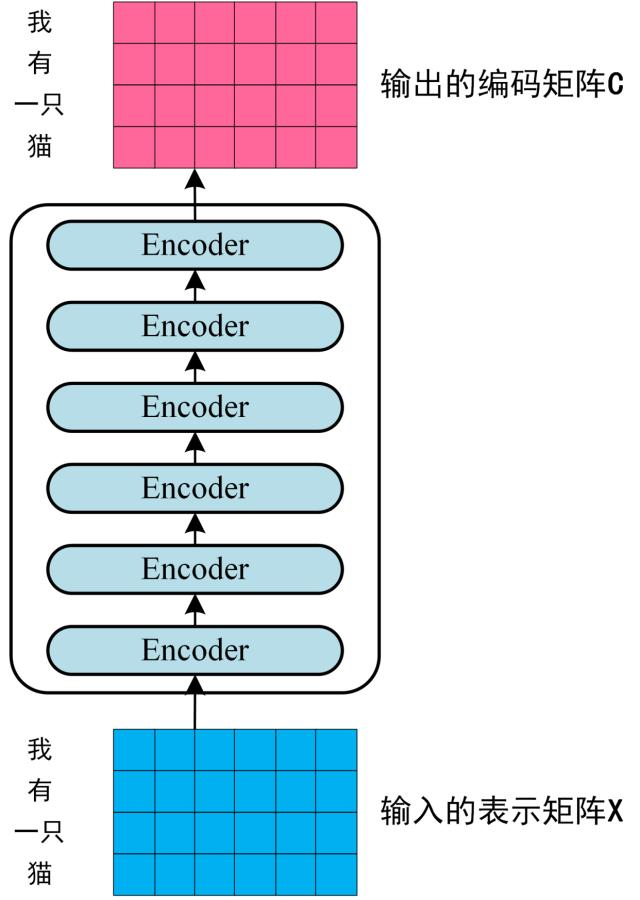
第二步:将第一步得到的向量矩阵传入编码器,编码器包含 6 个 block ,输出编码后的信息矩阵 C。每一个编码器输出的 block 维度与输入完全一致。
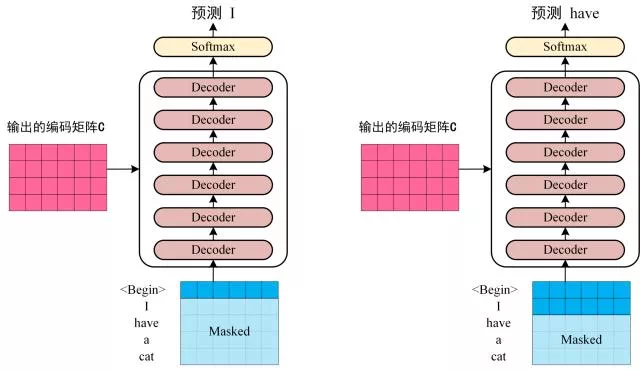
第三步:将编码器输出的编码信息矩阵 C 传递到解码器中,解码器会根据当前翻译过的单词 1~ i 依次翻译下一个单词 i+1,如下图所示:
下图展示了 Self-Attention 的结构。在计算时需要用到 Q(查询), K(键值), V(值)。在实践中,Self-Attention 接收的是输入(单词表示向量 x 组成的矩阵 X)或者上一个 Encoder block 的输出。而 Q, K, V 正是基于 Self-Attention 的输入进行线性变换得到的。
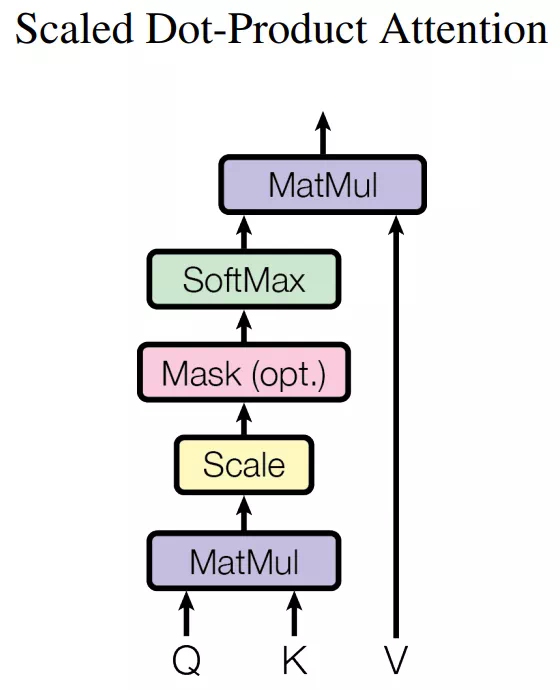
那么 Self-Attention 如何实现呢?
让我们来看一个具体的例子(以下示例图片来自博客 https://jalammar.github.io/illustrated-transformer/)。
假如我们要翻译一个词组 Thinking Machines,其中 Thinking 的词向量用 x1 表示,Machines 的词向量用 x2 表示。
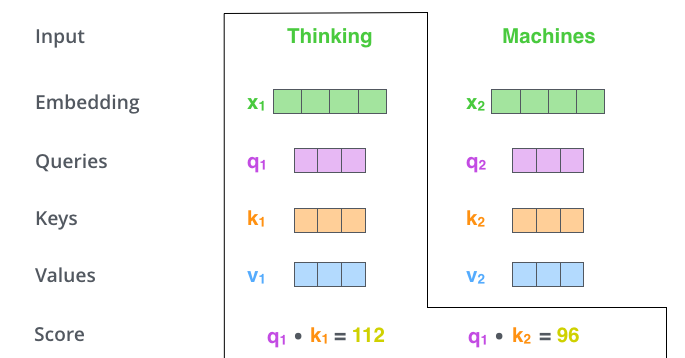
当处理 Thinking 这个词时,需要计算它与所有词的 attention Score,将当前词作为 query,去和句子中所有词的 key 匹配,得出相关度。用 q1 代表 Thinking 对应的 query vector,k1 及 k2 分别代表 Thinking 和 Machines 的 key vector。在计算 Thinking 的 attention score 时,需要先计算 q1 与 k1 及 k2 的点乘,同理在计算 Machines 的 attention score 时也需要计算 q_2 与 k1 及 k2 的点乘。如上图得到了 q1 与 k1 及 k2 的点乘,然后进行尺度缩放与 softmax 归一化,得到:
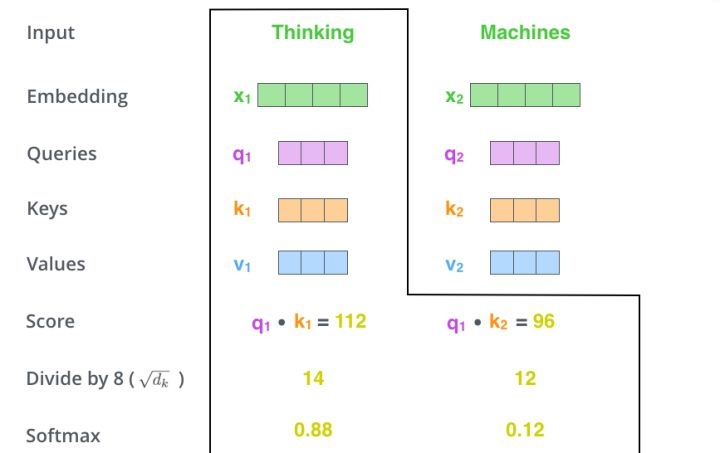
显然,当前单词与其自身的 attention score 最大,其他单词根据与当前单词的重要程度得到相应的 score。然后再将这些 attention score 与 value vector 相乘,得到加权的向量。
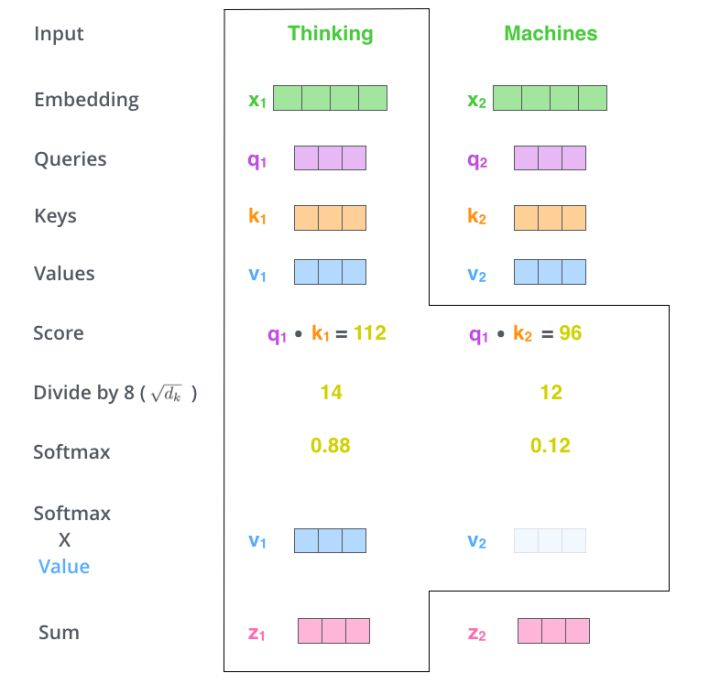
如果将输入的所有向量合并为矩阵形式,则所有 query, key, value 向量也可以合并为矩阵形式表示。以上是一个单词一个单词的输出,如果写成矩阵形式就是 Q*K,经过矩阵归一化直接得到权值。
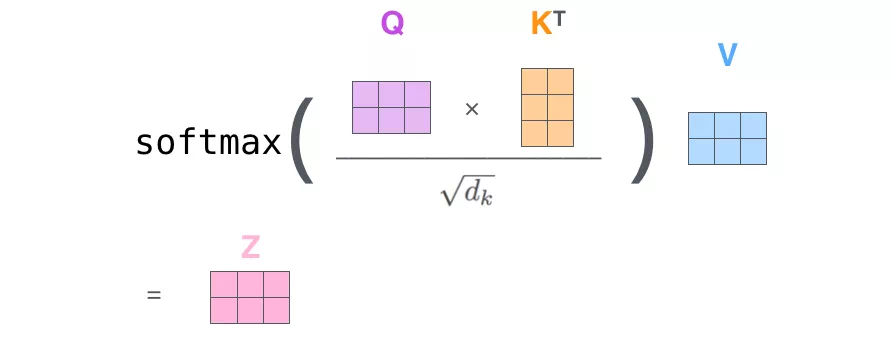
原始Transformer结构
原始的Transformer 采用Encoder-Decoder 架构,其包含Encoder 和Decoder 两部分。这两部分都是由自注意力模块和全连接前馈模块重复连接构建而成。其整体结构如图1.7所示。

其中,Encoder 部分由六个级联的encoder layer 组成,每个encoder layer 包含一个注意力模块和一个全连接前馈模块。其中的注意力模块为自注意力模块(query,key,value 的输入是相同的)。Decoder 部分由六个级联的decoder layer 组成,每个decoder layer 包含两个注意力模块和一个全连接前馈模块。
其中,第一个注意力模块为自注意力模块,第二个注意力模块为交叉注意力模块(query,key,value 的输入不同)。Decoder 中第一个decoder layer 的自注意力模块的输入为模型的输出。其后的decoder layer 的自注意力模块的输入为上一个decoder layer 的输出。Decoder 交叉注意力模块的输入分别是自注意力模块的输出(query)和最后一个encoder layer 的输出(key,value)。
Transformer构造模块
Transformer 是由两种模块组合构建的模块化网络结构。两种模块分别为:(1)注意力(Attention)模块;(2)全连接前馈(Fully-connected Feedforwad)模块。其中,自注意力模块由自注意力层(Self-Attention Layer)、残差连接(Residual Connections)和层正则化(Layer Normalization)组成。全连接前馈模块由全连接前馈层,残差连接和层正则化组成。两个模块的结构示意图如图1.5所示。

以下详细介绍每个层的原理及作用。
注意力层采用加权平均的思想将前文信息叠加到当前状态上。Transformer 的注意力层将输入编码为query,key,value 三部分,即将输入{x1, x2, ..., xt} 编码为{(q1, k1, v1), (q2, k2, v2), ..., (qt, kt, vt)}。其中,query 和key 用于计算自注意力的权重α, value 是对输入的编码。Transformer 自注意力的实现图1.6所示。

上图中,the output of the attention layer is O3 which the attention of the input sententice {x1, x2, x3}, writing as Attention(x) , 具体计算如下:

2. 全连接前馈层(Fully-connected Feedforwad Layer)
全连接前馈层占据了Transformer 近三分之二的参数,掌管着Transformer 模型的记忆。其可以看作是一种Key-Value 模式的记忆存储管理模块。全连接前馈层包含两层,两层之间由ReLU 作为激活函数。设全连接前馈层的输入为v, 全连接前馈层可由下式表示:
FFN(v) = max(0,W1v + b1)W2 + b2
其中,W1 和W2 分别为第一层和第二层的权重参数,b1 和b2 分别为第一层和第二层的偏置参数。其中第一层的可看作神经记忆中的key,而第二层可看作value。
3. 层正则化(Layer Normalization)
层正则化用以加速神经网络训练过程并取得更好的泛化性能[1]。设输入到层正则化层的向量为v = (v1,v2,...,vn),层正则化层将在v 的每一维度vi 上都进行层正则化操作。具体地,层正则化操作可以表示为下列公式:
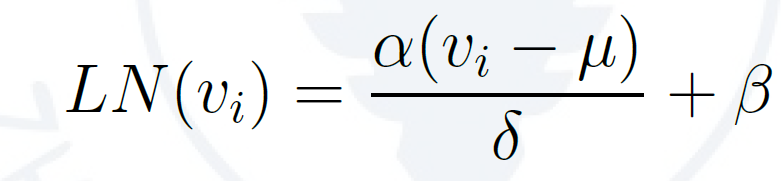

在实践中,当给定相同的查询、键和值的集合时, 我们希望模型可以基于相同的注意力机制学习到不同的行为, 然后将不同的行为作为知识组合起来, 捕获序列内各种范围的依赖关系 (例如,短距离依赖和长距离依赖关系)。 因此,允许注意力机制组合使用查询、键和值的不同 子空间表示(representation subspaces)可能是有益的。
为此,与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的
 多头注意力:多个头连结然后线性变换
多头注意力:多个头连结然后线性变换3. Transformer 语言模型
Top-P 随机采样方法
Top-P 方法可以克服生产文本“胡言乱语”和“枯燥无趣”。



- 上下文学习能力
- 常识推理能力
- 数学运算能力
- 代码生成能力
- 多模态理解能力